Nonces and Tokens
 I recently committed an extension to dwsCrypto lib module that exposes direct support for cryptographic nonces and tokens.
I recently committed an extension to dwsCrypto lib module that exposes direct support for cryptographic nonces and tokens.
Tips, Hints and Documentation Posts for SamplingProfiler and other Delphi Tools
I recently committed an extension to dwsCrypto lib module that exposes direct support for cryptographic nonces and tokens.
Here is a quick guide on migrating a project code from Google Code (SVN) to BitBucket (git) using TortoiseGIT, so with a GUI, and with no cryptic command line in sight.
Migrating Wiki/Issues is a bit more involved and not covered here. Migrating downloads has to be done by re-uploading to BitBucket (but at least BitBucket supports binary downloads).
Hash, IndexOf, Lookup, Performance, Search, Sorted, String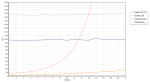
 As a followup to the previous String Lookup: Hash, Sorted or Unsorted here is a look at what happens for longer strings.
As a followup to the previous String Lookup: Hash, Sorted or Unsorted here is a look at what happens for longer strings.
When the string you’re searching have more than a dozen characters, and you only have a few hundreds of them, a clear winner emerges.
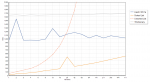
 When looking up a string, what is the fastest strategy?
When looking up a string, what is the fastest strategy?
A hash map, a sorted list or an unsorted list?
Of course it depends on how many strings you have, but where are the cutoff points?
Here is a quick test, and an interesting tidbit is uncovered…
(more…)
 A trivial way to turn a case-sensitive String hash function into a case-insensitive one is to to pass a lower-case (or upper-case) version of the String.
A trivial way to turn a case-sensitive String hash function into a case-insensitive one is to to pass a lower-case (or upper-case) version of the String.
However, in our days of Unicode strings, this is not innocuous…
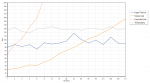
 Following a recent post by A. Bouchez about an optimized CRC32 hash, I took it as an opportunity to re-run a small String Hashing Shootout on the worst hash function collision torture test I know: ZIP codes in UTF-16 (Delphi’s default String format).
Following a recent post by A. Bouchez about an optimized CRC32 hash, I took it as an opportunity to re-run a small String Hashing Shootout on the worst hash function collision torture test I know: ZIP codes in UTF-16 (Delphi’s default String format).
 We’ve all encoutered reCAPTCHA, as it’s one of the few effective ways to protect form submissions from bots on the internet.
We’ve all encoutered reCAPTCHA, as it’s one of the few effective ways to protect form submissions from bots on the internet.
Acquired by google in 2009, it comes with multiple plugins for various web environment, here is a plugin for DWScript.
 Here is a small snippet to illustrate how you can perform a conditional HTTP 301 redirection in DWScript, and can serve as an illustration on serving “special” HTTP responses.
Here is a small snippet to illustrate how you can perform a conditional HTTP 301 redirection in DWScript, and can serve as an illustration on serving “special” HTTP responses.
This is useful when a website is moved from one domain to another, but the server is not, ie. if both old and new domains are hosted by the same server.
An utility that was added to the DWScript sample WebServer during the 4 TeraPixel Mandelbrot experiment is the BackgroundWorkers API.
This is a rather low-level threading facility that can work well with Global Queues to handle background tasks or serializing tasks.