Slim Reader/Writer Locks Rock!
 I recently posted abut the new Slim R/W Locks introduced with Vista, and how they were vastly more efficient than TMREWS.
I recently posted abut the new Slim R/W Locks introduced with Vista, and how they were vastly more efficient than TMREWS.
Apparently, they’re also more efficient than Critical Sections…
I recently posted abut the new Slim R/W Locks introduced with Vista, and how they were vastly more efficient than TMREWS.
Apparently, they’re also more efficient than Critical Sections…
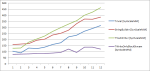
Here are a few findings on Multi-Read Exclusive-Write Synchronizer from a recent upgrade of DWScript‘s GlobalVar functions.
I ran some comparisons between a plain Critical Section, Delphi’s TMultiReadExclusiveWriteSynchronizer and Windows Slim Reader/Writer Lock, of which an implementation was added to the dwsXPlatform unit.
 Here is a small utility I made whose purpose is to flush (empty) the Windows file cache. It can also flush and purge memory working sets, standby and modified lists.
Here is a small utility I made whose purpose is to flush (empty) the Windows file cache. It can also flush and purge memory working sets, standby and modified lists.
It can be useful to reduce memory usage of a particular VM (on a host with dynamic memory) or for testing and bench-marking purposes.
![]() Delphi offers two ways of enumerating files in a directory and its sub-directories, the first is the classic (and buggy) FindFirst/FindNext, the second is IOUtils TDirectory.GetFiles and not very efficient.
Delphi offers two ways of enumerating files in a directory and its sub-directories, the first is the classic (and buggy) FindFirst/FindNext, the second is IOUtils TDirectory.GetFiles and not very efficient.
Here is why and how I implemented DWScript‘s dwsXPlatform.CollectFiles, and a tip about getting a small system-wide boost as a bonus.
 [This is a guest post, written by Primož Gabrijelčič, www.
[This is a guest post, written by Primož Gabrijelčič, www.
One thing interested me since I started reading Eric’s series on string concatenation performance – how would different memory managers compare in a multi-threaded scenario. Today I decided to spend an hour finding out…
edit 18/11: the tests were run with debug mode, which affected TTextWriter very negatively (TWOBS is also affected a negatively, but less, and StringBuilder and Trivial aren’t affected much). I’ll be repeating tests with more memory managers and in more stable conditions in the next few weeks.
 After looking at String concatenation and String Building in Delphi, and as a conclusion, it’s time to have a brief look at what happens in multi-threaded settings, such as in a server pushing JSON, XML or some other text data.
After looking at String concatenation and String Building in Delphi, and as a conclusion, it’s time to have a brief look at what happens in multi-threaded settings, such as in a server pushing JSON, XML or some other text data.
 As a followup to the String Concatenation article, let’s take a look at a less trivial case: what if instead of concatenating a couple strings, you want to concatenate a few hundred?
As a followup to the String Concatenation article, let’s take a look at a less trivial case: what if instead of concatenating a couple strings, you want to concatenate a few hundred?
Sounds like a task at which TStringBuilder should excel, but one should never assume, and always measure.
 You may all know about String concatenation in Delphi, but do you know about the implicit String variables the compiler may create for you?
You may all know about String concatenation in Delphi, but do you know about the implicit String variables the compiler may create for you?
Along with the implicit variables come implicit exception frames, and a whole lot of hidden stack juggling, which can quickly become hidden complexity bottlenecks.
 Work and processing classes are typically short-lived, created to perform one form of processing or another then freed. They can be simple collections, handle I/O of one kind of another, perform computations, pattern matching, etc.
Work and processing classes are typically short-lived, created to perform one form of processing or another then freed. They can be simple collections, handle I/O of one kind of another, perform computations, pattern matching, etc.
When they’re used for simple workloads, their short-lived temporary nature can sometimes become a performance problem.
(more…)
 The built-in time-stepping support for the upcoming release of
The built-in time-stepping support for the upcoming release of