
 Committed to daNeuralNet a first working version of a JIT for matrix-vector multiplication that relies on the FMA instruction set (Fused Multiply and Addition).
Committed to daNeuralNet a first working version of a JIT for matrix-vector multiplication that relies on the FMA instruction set (Fused Multiply and Addition).
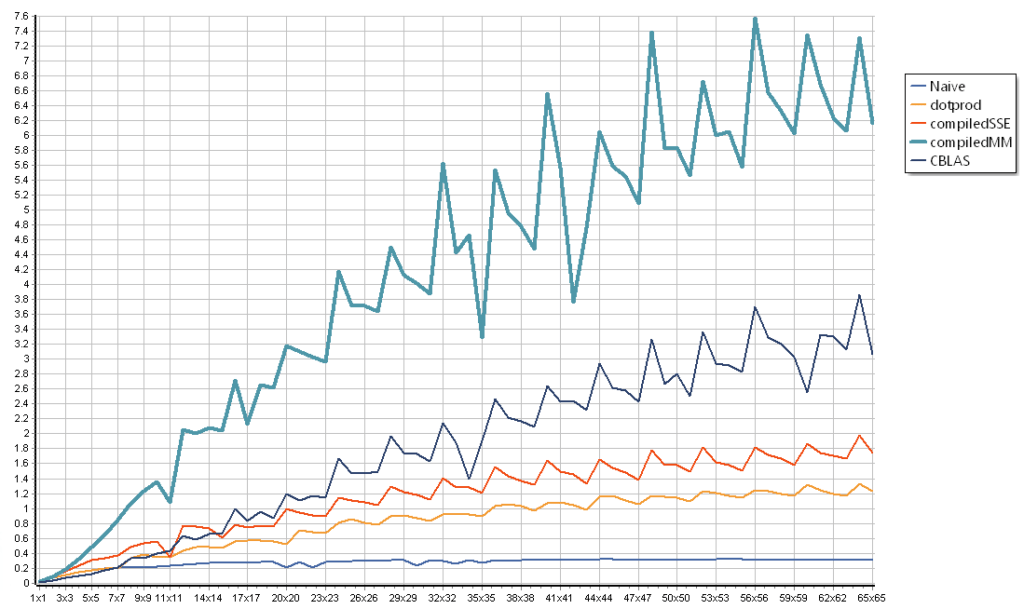
This version generates code that is up to twice faster than the OpenBLAS for matrix sizes up to CPU cache size (100×100 to 200×200 usually), and maintains a marginal lead for larger sizes, though those are bound by memory bandwidth. The performance profile is similar on both AMD and Intel CPUs.
The idea of the JIT is that it compiles a function that only knows to multiple an exact matrix size and topology (row major & dense right now). This allows to do away with conditional branches, leaving only at most two fixed loops, with hard-coded preambles and postambles.
The chart below shows the number of elements per cycle for increasing matrix sizes, in the case of a square matrix-vector multiplication. For small-ish sizes, the JIT (listed as “compiledMM”) maintains a comfortable lead.
The chart below zooms out to show the behavior for larger sizes. As you can see, performance hits a wall, a memory bandwidth wall. The CPU here is an Intel E3-1240v6, and the L1/L2/L3 caches (respectively 128 kB, 1 MB and 8MB on that CPU) are quite obvious.
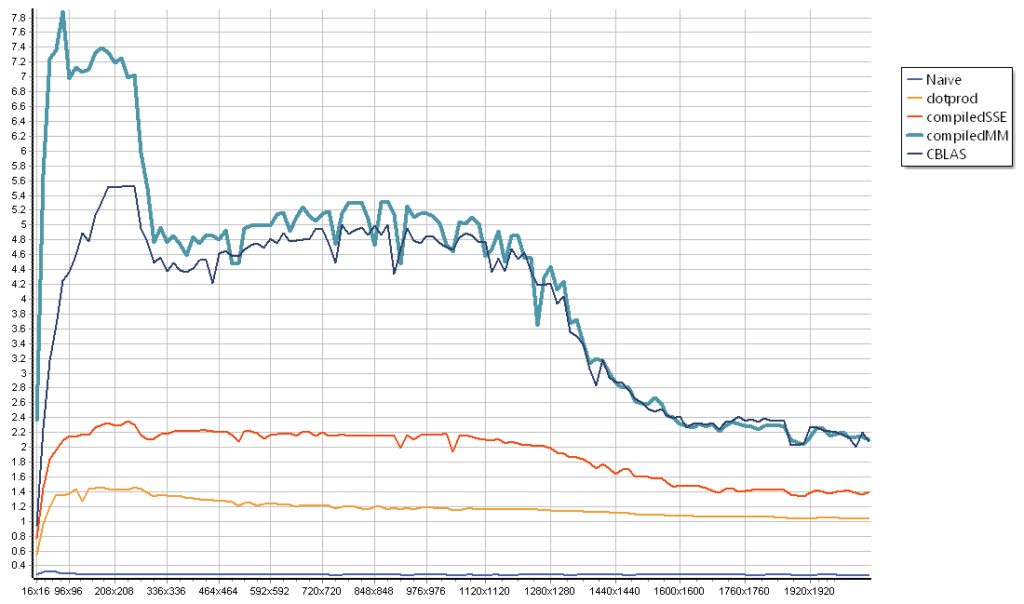
All the charts above are for a single-thread, however the memory wall does not bode well for multithreaded potential. Previous tests with OpenBLAS already showed that multithreaded improvements are very limited.
In the context of neural networks, the consequence is that for large tensors, what you need is not raw gigaflops (as often mentioned in literature), but gigabytes/second.

Nice Week-End work!
🙂