

Algorithm Performance and Memory Manager
We get an interesting insight into speed of memory managers if we compare times for one algorithm running on different memory managers.
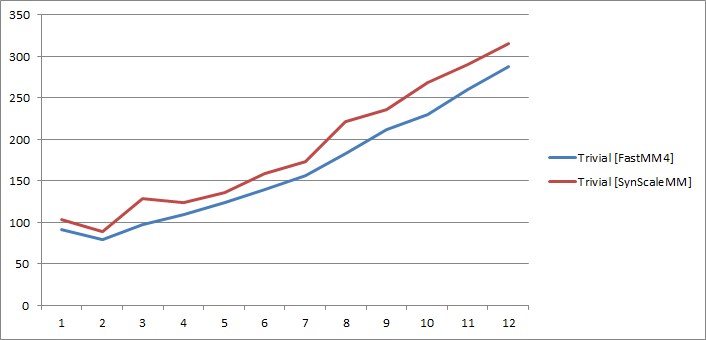
In the trivial case, both FastMM4 and SynScaleMM behave almost the same, while the NN was so slow I couldn’t even show it on the chart.
An interesting observation – in both algorithms two threads performed better than one, which is really a surprise for me as two threads also have to execute (both together) twice as much work. So in a two-thread case, each thread was working faster than in a single thread case.
This is an interesting side-effect of the two processor setup: when a single thread is busy, the OS will tend to switch it across processors to spread the load, and when switched from processor, the L1 and L2 cache are lost, the processor needs to read everything from RAM again. When the one thread is pinned to a processor via its thread affinity, the issue goes away.
For two threads, the OS is apparently smart enough to switch keep one thread on each processor.
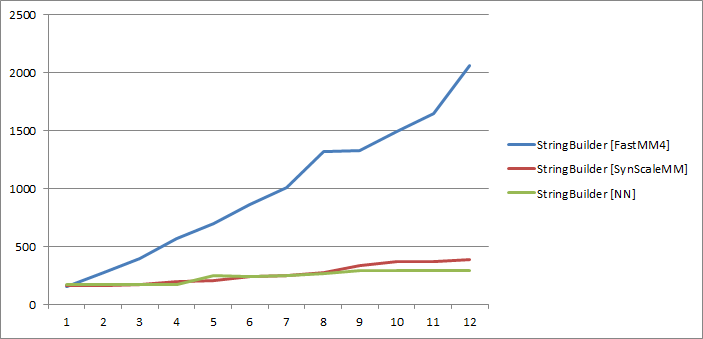
We already know that StringBuilder is performing substandardly with the FastMM, but from this graph we also see that the problem is not that much in the StringBuilder implementation but in the FastMM, where multiple threads are fighting for the same memory manager (because they allocate blocks of the same size). Both SynScalMM and NN are performing well, with NN taking a small lead on >8 cores.
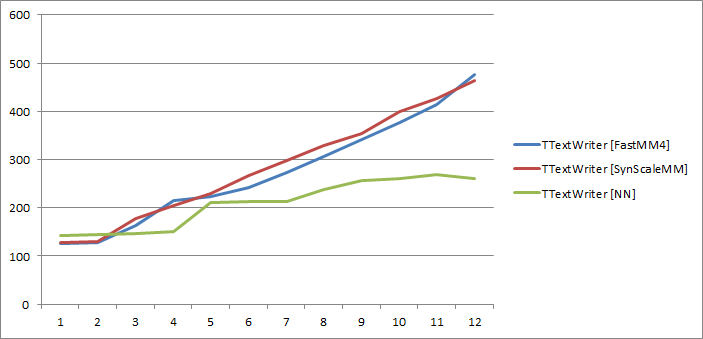
This was in my opinion the most surprising result of the test – not the good performance of the NN, but practically identical performance of FastMM4 and SynScaleMM. It looks that under some circumstances FastMM4 performs quite well even in multithreaded tests.
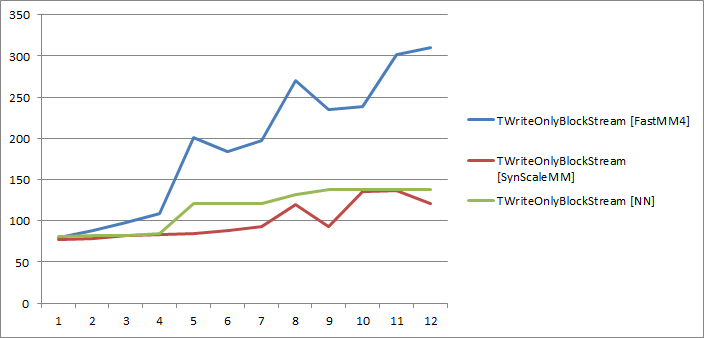
In the last comparison – TWriteOnlyBlockStream – SynScaleMM and NN are performing equally well with SynScaleMM being slightly faster while FastMM4 is about 2,5 times slower. The weird spikes in the FastMM4 graph are probably measurement artifacts.


Some of the benchmark screens are missing the title so it is hard to tell what they are benchmarking…
You could also include to your test this memory manager: https://code.google.com/p/scalemm/ (not the same as syncscalemm).
BTW: nice idea with Pierre on a Kickstarter!:)
A important thing you need to know, is that SynScaleMM is actually the same as ScaleMMv1, which runs on top of FastMM (which explains similar performance). However, my initial Proof of Concept (v1) only contained a memory manager per thread for small memory (1mb) is always directly requested from Windows (same as FastMM).
(I also tried to make ScaleMM3 with a very different approached, but it turned out to be much slower…)
I was also busy with testing on my Quad core, and ScaleMM2 scaled (almost) linear!
I also tested it with Google’s TCmalloc, which has a similar performance as SMM2 (but never releases it memory to Windows!)
The MSVCRT MM (Win7) seems to scale fine with stringbuilder (but being slower than all others). But with trivial string it performs very bad! I think it has the same problem as NN: it does a full realloc everytime. Whereas FastMM, ScaleMM and TCmalloc do some kind of “smart capacity” expanding (e.g. alloc 25% more space so need to do a full realloc+move for every byte!).
I will mail you the necessary sources (and my results so far)
At least it shows that strings are memory manager bound in Delphi: with the default mm (fastmm) it stays at 25% cpu on my quad core with 8 threads due to the global lock of fastmm. But with other MM’s it will reach 100% cpu, so making full usage of all cores!
Fascinating! I can make a guess about what NN is – a well-known memory manager that begins with N? 😉
I have been working on a new memory manager myself for some time, although it’s been on the back-burner for a few months while traveling. It aims to have good multithreaded performance, ie it’s designed from the outset for a situation where many threads allocate and free at the same time. Unfortunately it’s not done yet, not even to a beta state. However, I will try to find time to continue working and run your performance tests using it…
Nice article!
BUT there is an other factor that is important : fragmentation. For long running / memory hog applications this can be a problem also (can cause OutofMemory errors even ICO plenty free memory)
Unfortunately I don’t know how can measue it…
Please do not use SynScaleMM, which is a Proof Of Concept, never to be used on production.
Try ScaleMM2 which is much more stable and also fast/tuned.
I just checked the source code.
I would have rather written in this case:
function UseTextWriter : String;
var
i : Integer;
tw : TTextWriter;
st: TRawByteStringStream;
begin
st := TRawByteStringStream.Create;
tw := TTextWriter.Create(st,65536);
try
for i := 1 to NB do begin
tw.AddString(#13#10'Eating apple #');
tw.Add(Int64(i));
end;
tw.Flush;
Result:=Ansi7ToString(st.DataString);
finally
tw.Free;
st.Free;
end;
end;
Since the default buffer may be too small for such generation.
What is pretty “unfair” in the comparison is that you include a UTF-8 to Unicode conversion during the test, only for TTextWriter!
Perhaps using Ansi7ToString() may be a bit faster (even if our UTF-8/Unicode conversion is pretty optimized).
But in all cases, other classes DID NOT do any such conversion.
You are comparing apples with oranges, here.
All those drawings are pretty nice, but…
Which kind of program will do a fixed pattern of string + number concatenation in loop in all threads at once?
A benchmark. Only a benchmark.
More general tests as we use in our regression and performance tests (including JSON creation of several kind of data, JSON parsing, HTTP client/server, RTTI access, caching, search, database backend with disk read/write, logging, with up to 50,000 concurrent clients, IOCP and a thread pool).
What I like very much is feedback for mORMot users using it on production – like http://synopse.info/forum/viewtopic.php?pid=4732#p4732
My current challenge is to provide some code to http://www.techempower.com/benchmarks/
I’m adding MVC support to mORMot currently, using JavaScript BTW.
Here we will see how it works. In the real world…
🙂
Thanks for taking the time to do the comparisons and write them up. Unfortunately, using different scales on your graphs makes it difficult to appreciate the actual differences. This is a cardinal sin of visually representing quantitative information. If you’re interested in how to present information visually, then I highly recommend reading some of Edward Tufte’s book, such as “The Visual Display of Quantitative Information”. Link below.
http://www.edwardtufte.com/tufte/books_vdqi
Interesting stuff. We use the nexusdb memory mananger in FinalBuilder and Automise. We have a bunch of benchmark/test FinalBuilder projects (which exercise the stepping engine with multiple threads), and for those projects the nexus memory manager typically performs twice as fast as FastMM4.
I found a small bug in the test source: in
function UseWOBS : String;, the linewobs.WriteString(i);won’t compile since i is an integer, and in what I think is the latest version of DWS, which I just downloaded, there is no overload for integers, only strings.I replaced it with
wobs.WriteString(IntToStr(i));instead.@A. Bouchez IMHO TTextWriter cannot be used because its not UTF16 ready there for TStringBuilder is still the clear choice for us until Embarcadero improves it.